Unter https://jupyterhub.urbanstack.de/ steht eine JupyterHub-Installation bereit,
die es angemeldeten Benutzern der Plattform ermöglicht,
in persönlichen JupyterLab-Instanzen Jupyter Notebooks zu entwickeln und auszuführen.
Aus dem Gov Hub kann mittels eines Menüpunktes dorthin navigiert werden.
Link zu JupyterHub
Hilfsbibliothek
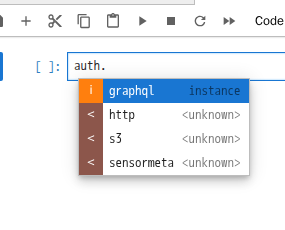
Die Seite Hilfsbibliothek beschreibt die integrierte Hilfsbibliothek für Zugriff auf die Plattform.
Autovervollständigung
Durch Drücken von Tab kann eine Autovervollständigung ausgelöst werden.
Autovervollständigung
Jupyter Scheduler
Der Jupyter Scheduler ist ein für jeden Benutzer vorinstalliertes Plugin, mit welchem Benutzer ihre Skripts in zeitlichen Abständen zu bestimmten Zeitpunkten automatisiert ausführen lassen können. Dies ist momentan nur mit Python-Notebooks möglich.
Erstellen eines Notebooks
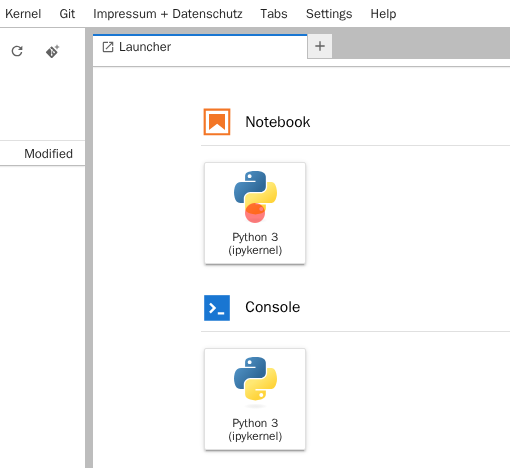
Erstellen Sie über das Dashboard / bzw. den Launcher ein beliebiges Notebook unter dem Reiter "Notebook".
Das Notebook wird erstellt und geöffnet. Das (Python-)Notebook erhält den Standardnamen
"Unititled.ipynb". Notebooks anderer Sprachen haben jeweils verschiedene Endungen.
Hinweis
Beim erstmaligen Speichern einer Datei erscheint ein Pop-up in welchem Sie den Dateinamen ändern können.
Ansonsten geht dies über das Aufrufen des Kontextmenüs mit einem Rechtsklick auf die Datei.
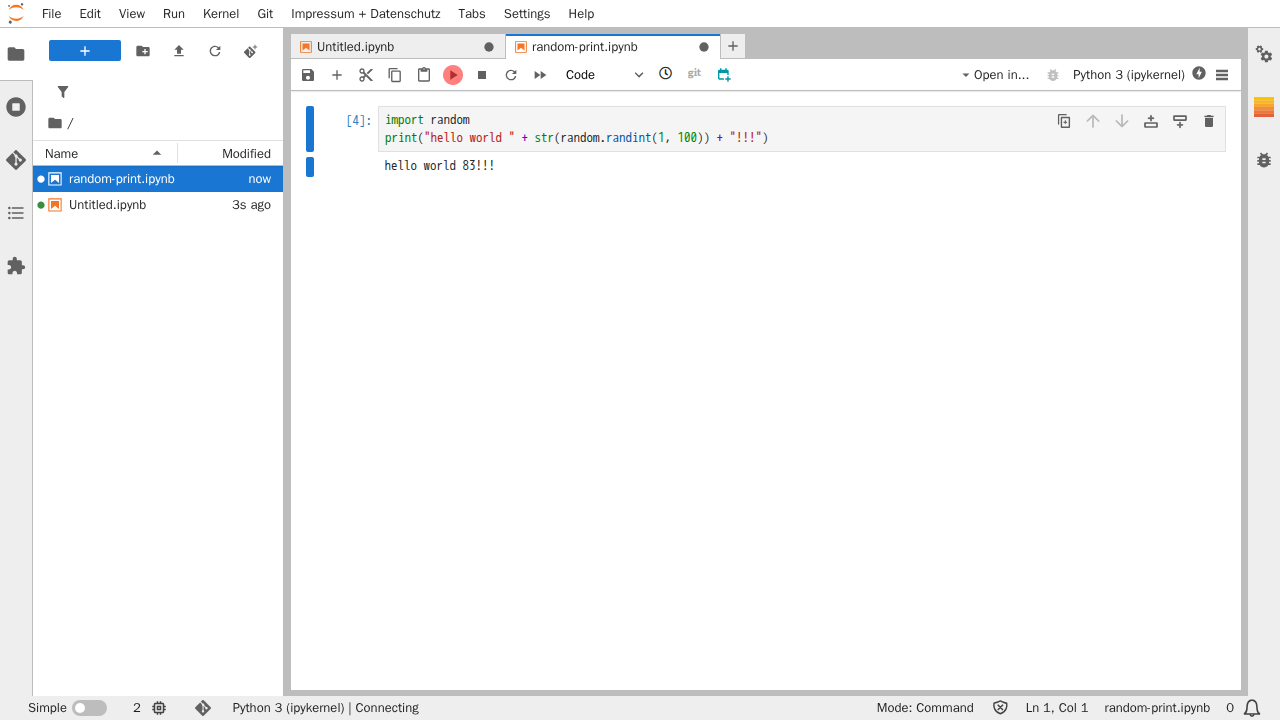
Öffnen Sie das Notebook und entwickeln Sie Ihre Anwendung, welche später in zeitlichen Abständen wiederholt aufgerufen wird. Testen Sie anschließend Ihre Anwendung durch einen klick auf den "Ausführen"-Knopf. Korrigieren Sie eventuelle Fehler.
Hinweis
Vergewissern Sie sich ob Sie Ihre Änderungen bereits gespeichert haben, um Verluste von Fortschritt zu vermeiden.
Einrichten eines Notebook-Jobs
Um ein Notebook-Job anzulegen, klicken Sie hierfür auf den Knopf mit dem blauen Kalender Symbol.
Es öffnet sich ein neuer Reiter "Notebook-Jobs". In diesem Fenster lassen sich verschiedene Einstellungen für den Scheduler vornehmen.
Job name: Name des Notebook-Jobs. Standardmäßig der Dateiname. Kann nach belieben umbenannt werden.
Input File: Der Pfad zur Datei die beim Job ausgeführt werden soll. Standardmäßig die Datei von welcher aus das Fenster geöffnet wurde.
Run job with input folder: Der Job wird im angegebenen Verzeichnis ausgeführt. Standardmäßig im dem selben Verzeichnis wo sich die Anwendung (bzw. die Input File) befindet. Die Anwendung hat dann Zugriff auf die Dateien im angegebenen Verzeichnis (z.B. einer Text-Datei).
Ausgabe Formate:
Notebook: Gibt eine Notebook-Datei (.ipynb) zurück, mit der man weiterarbeiten kann. Mit Verlauf und Ergebnis.
HTML: Gibt den Verlauf und das Ergebnis des Notebook-Jobs als HTML zurück. Im Gegensatz zur Notebook Ausgabe, kann man hiermit nicht weiterarbeiten.
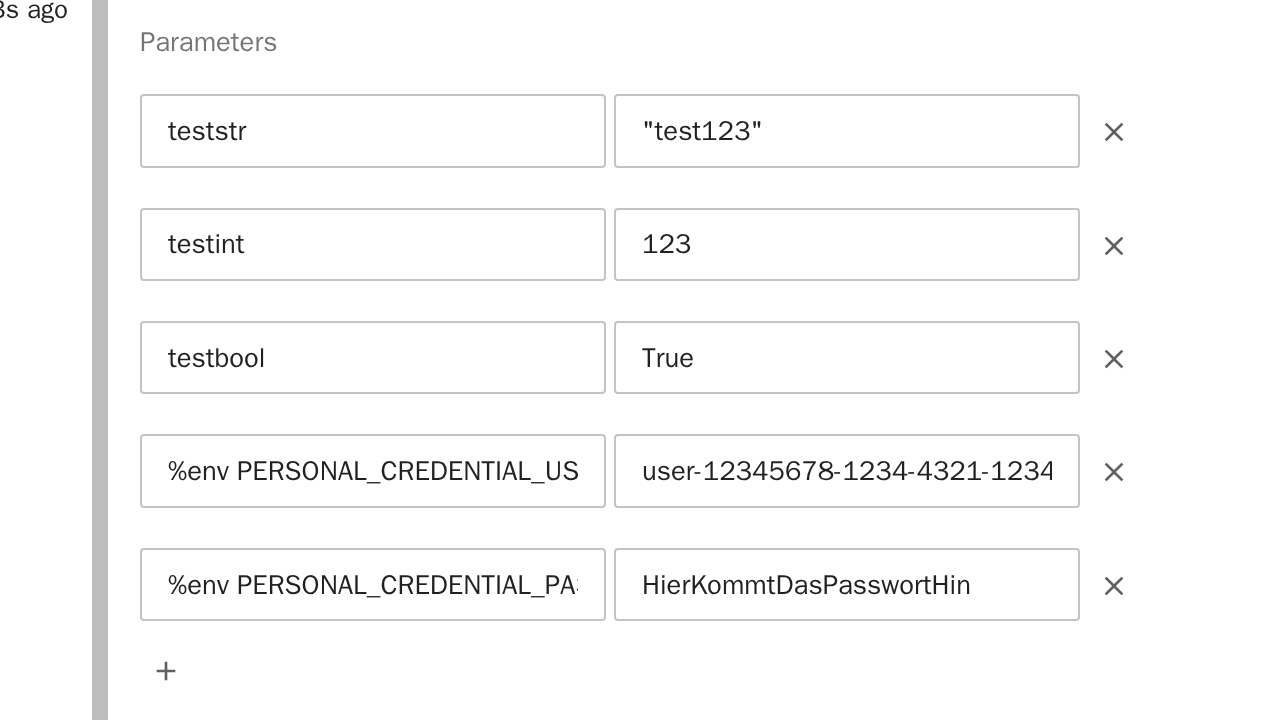
Parameters: Hier können Parameter für die Job-Ausführung eines Notebooks verwaltet werden. Fügen Sie neue Parameter mit dem "+"-Symbol, bestehend aus einem Namen (linke Spalte) und einem Wert (rechte Spalte), hinzu.
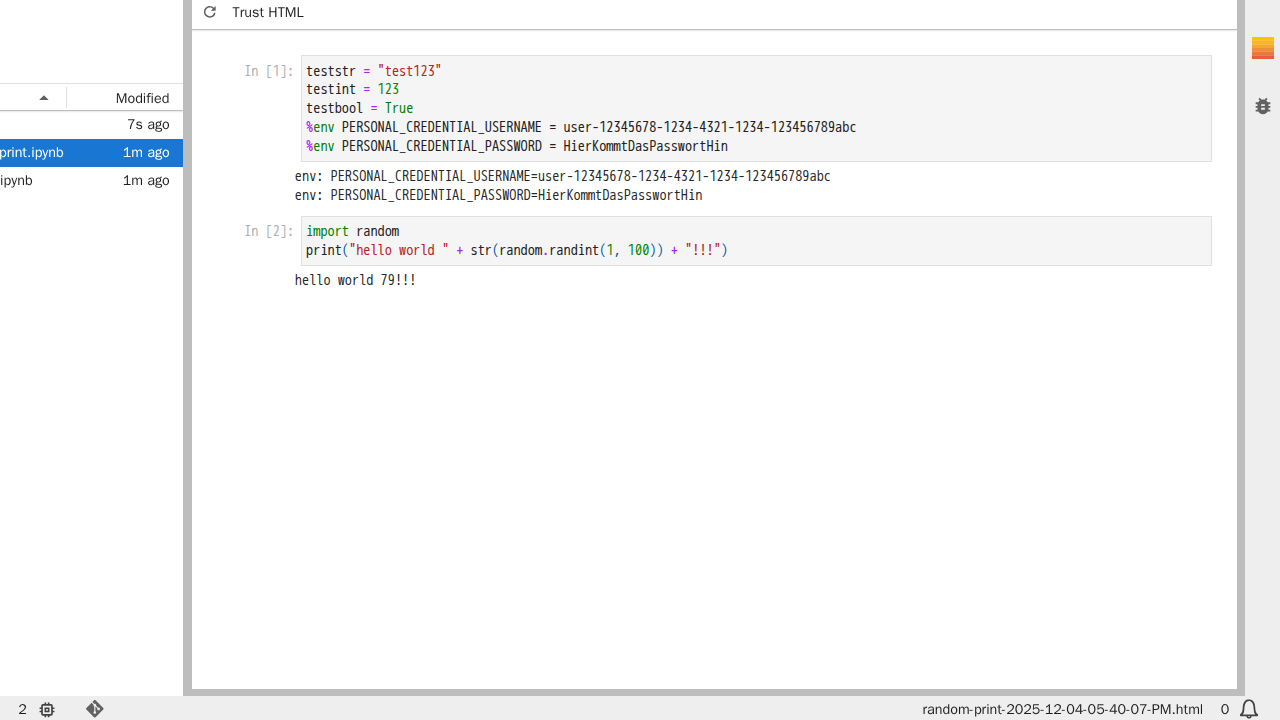
Nutzt das Skript die login-Methode der Urbanstack-Hilfsbibliothek, muss das "Personal Credential" hier als Umgebungsvariablen (PERSONAL_CREDENTIAL_USERNAME und PERSONAL_CREDENTIAL_PASSWORD) hinterlegt werden:
Als Parameterwerte kann man alle Built-In Types in Python verwenden. Hier ein paar Beispiele:
Zahlen (Integer, Decimal, etc.) --> z.B. 55 oder 1.2
Texte (String, Char) --> z.B. "Beispiel" oder 'B' (die "" oder '' sind hier wichtig!)
Wahrheitswerte (Boolean) --> True oder False
Dictionary (Dict) --> z.B. {"Beispiel": 1}
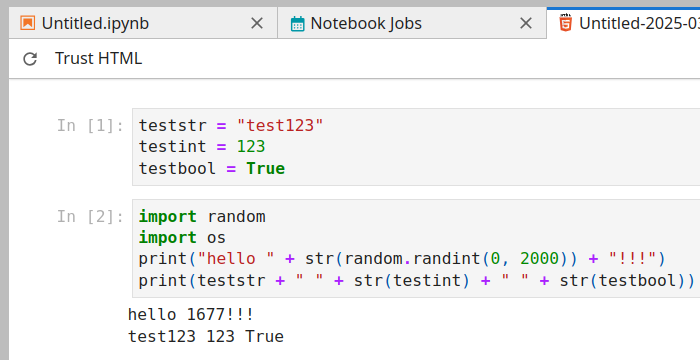
Eine Beispiel HTML-Ausgabe für einen Notebook-Job mit Parametern sieht in etwa so aus:
Die angegebenen Parameter werden vor dem eigentlichen Skript in einer eigenen Zelle ausgeführt.
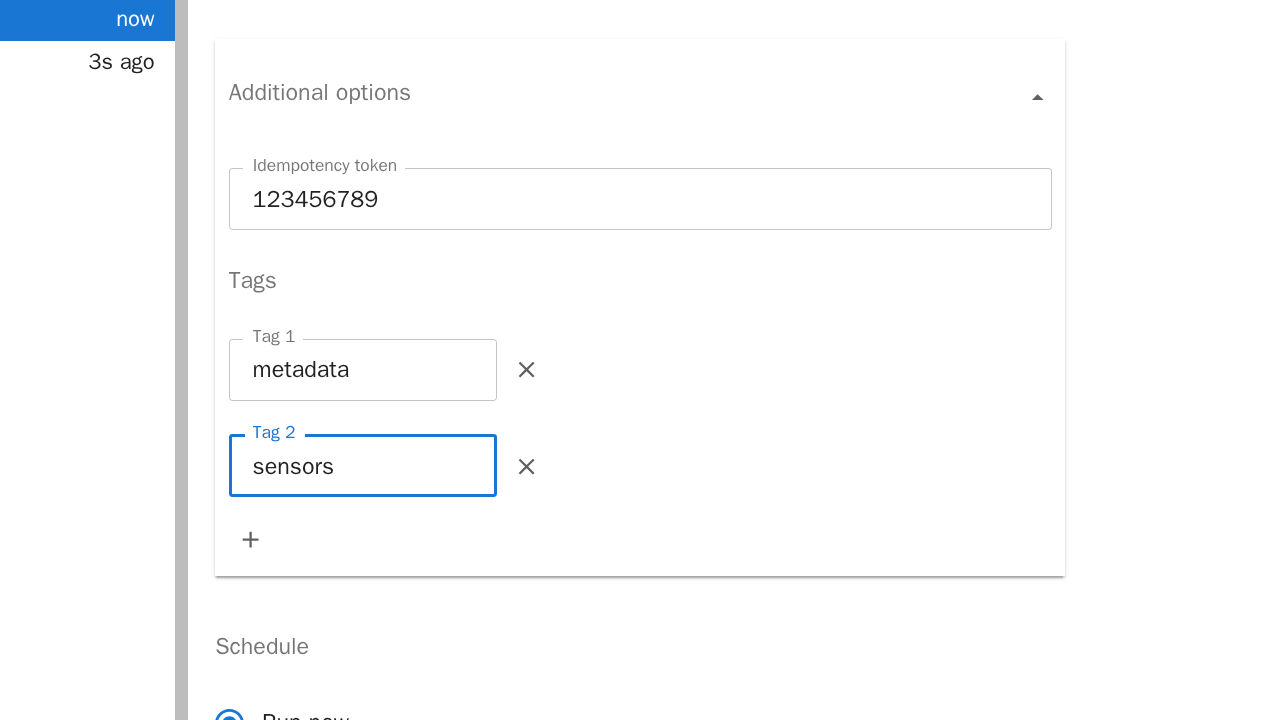
Additional options:
Idempotency Token: Dem Job kann eine beliebige ID mitgegeben werden. Diese verhindert doppelte Job-Durchläufe durch z.B. Netzwerkfehler.
Tags: Wörter nach denen gefiltert/sortiert werden kann (aktuell nicht über das Jupyter UI möglich).
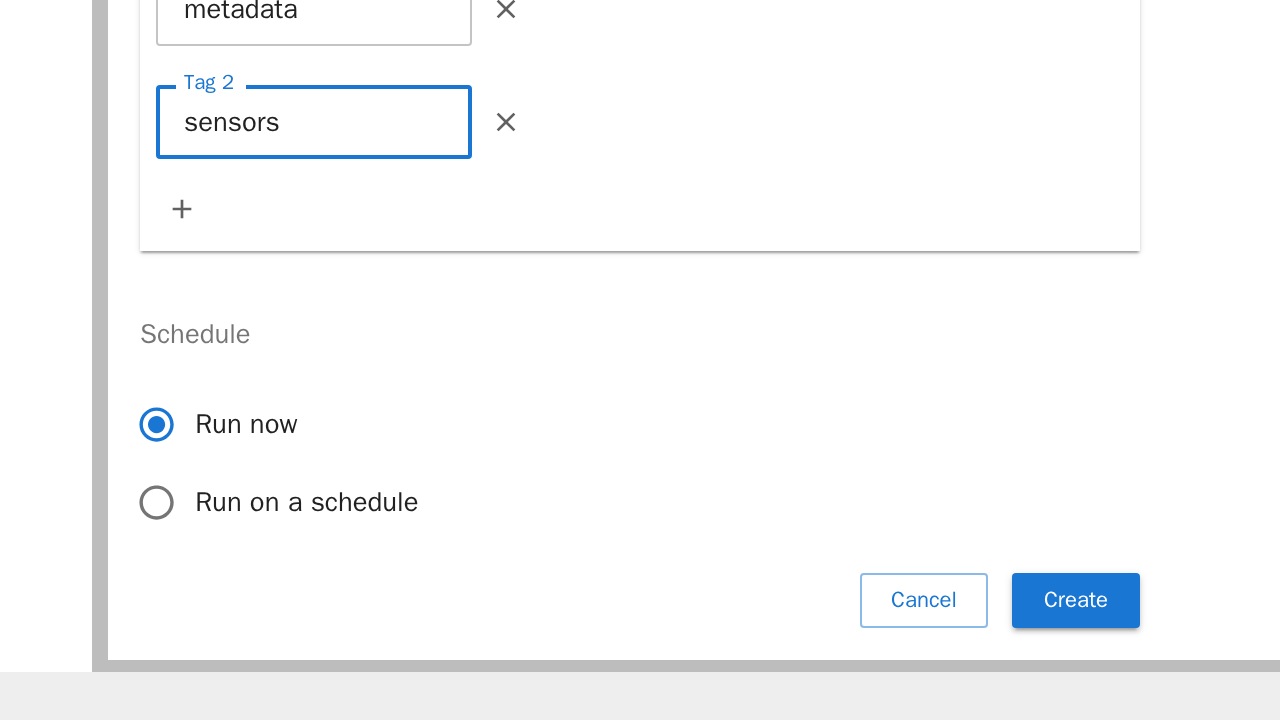
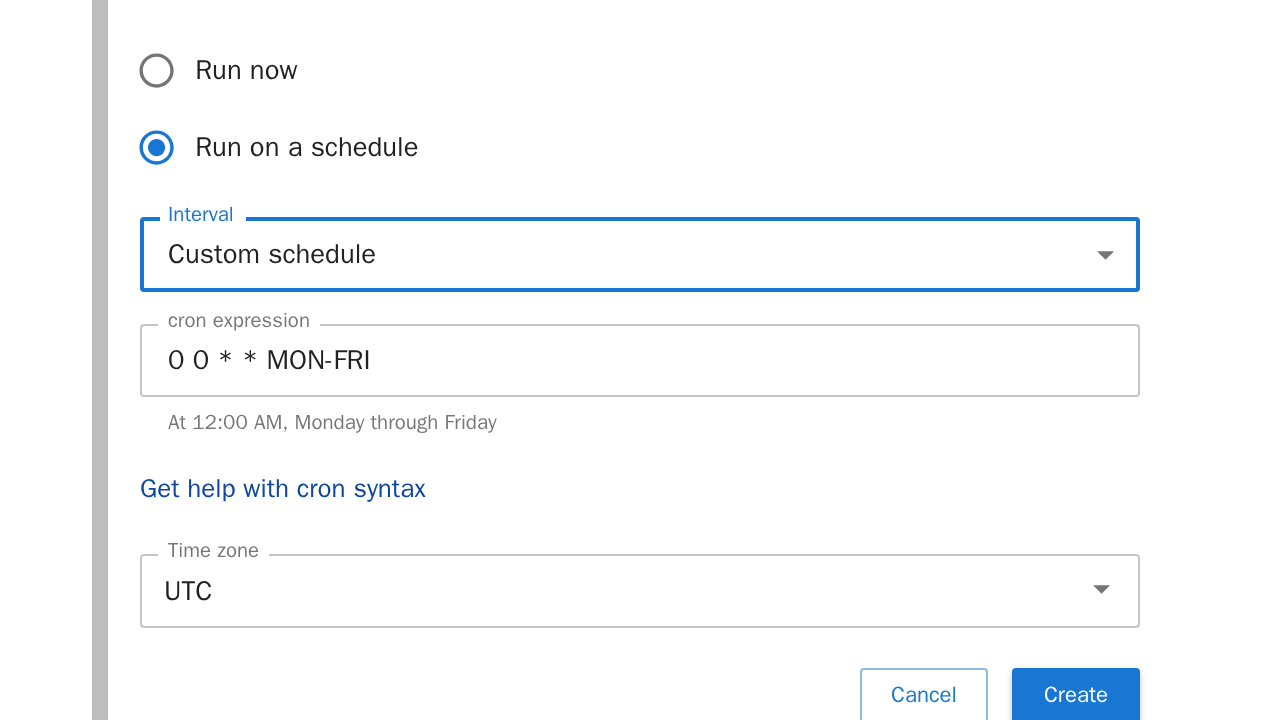
Schedule: Beim Schedule lässt sich einstellen, wann der Job laufen soll.
Wählt man "Run now" aus, läuft der Job einmalig direkt nach dem Erstellen.
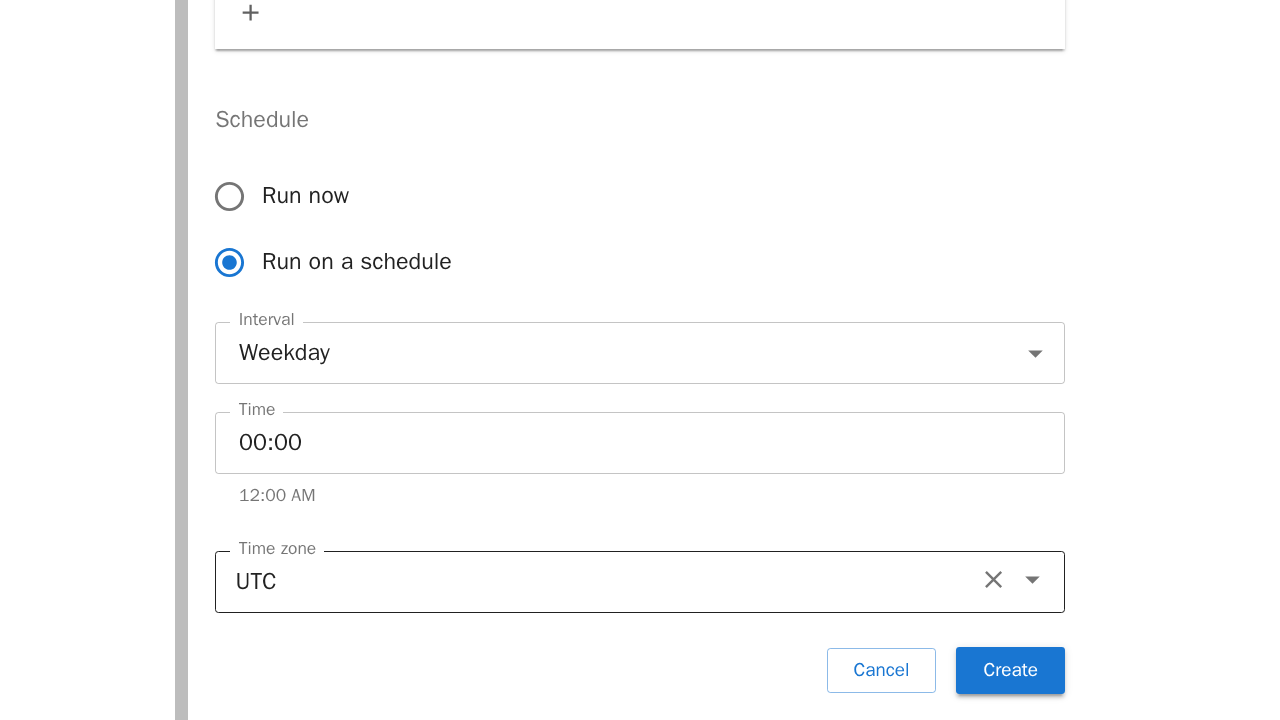
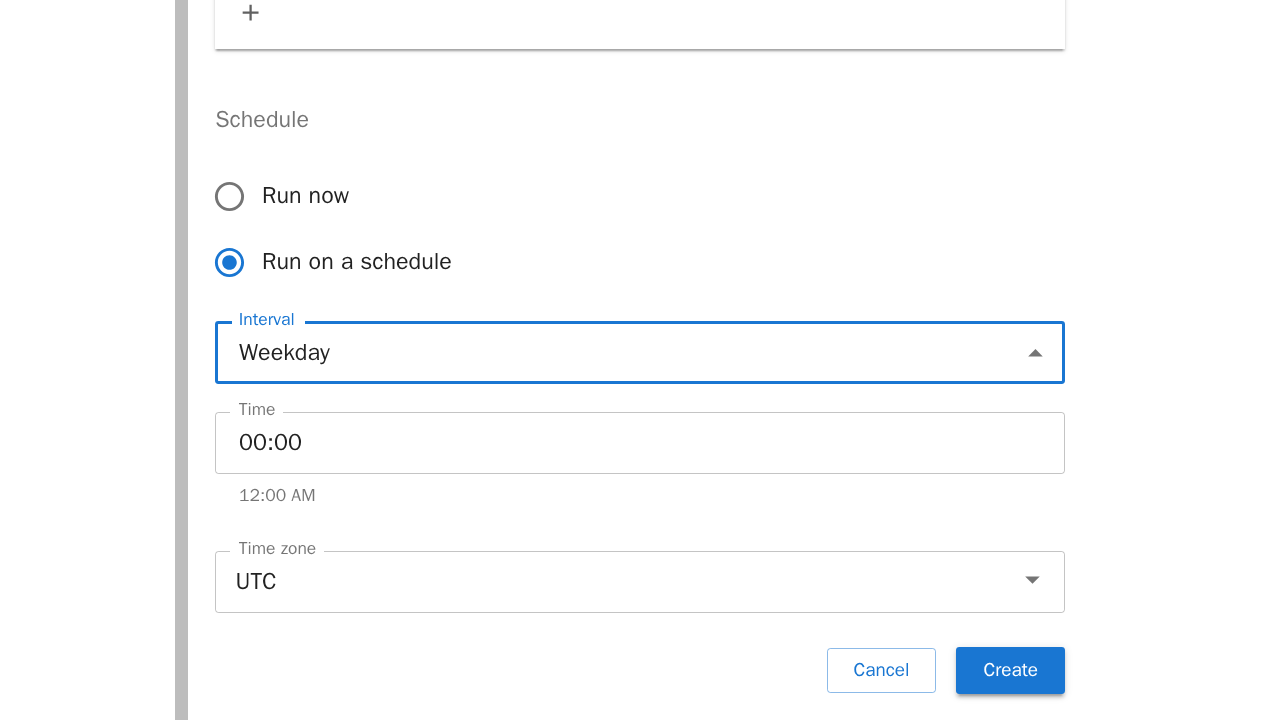
Wählt man stattdessen "Run on a schedule" aus, kann man zwischen verschiedenen Zeitintervallen auswählen. Der Job läuft dann im angegebenen Zeitintervall. Vorgegebene Zeitintervalle sind:Minuten, Stunden, Tage, Wochen, Werktage, Monate oder Benutzerdefiniert:
Wählt man "Benutzerdefiniert" als Zeitintervall aus, kann man das Zeitintervall mittels einer CRON-Expression individuell gestalten.
Sind alle Einstellungen soweit erledigt, drückt man auf den "Create"-Knopf um den Job zu erstellen.
Warnung
Nach dem Erstellen lassen sich nur "Input file" und "Schedule" bearbeiten!
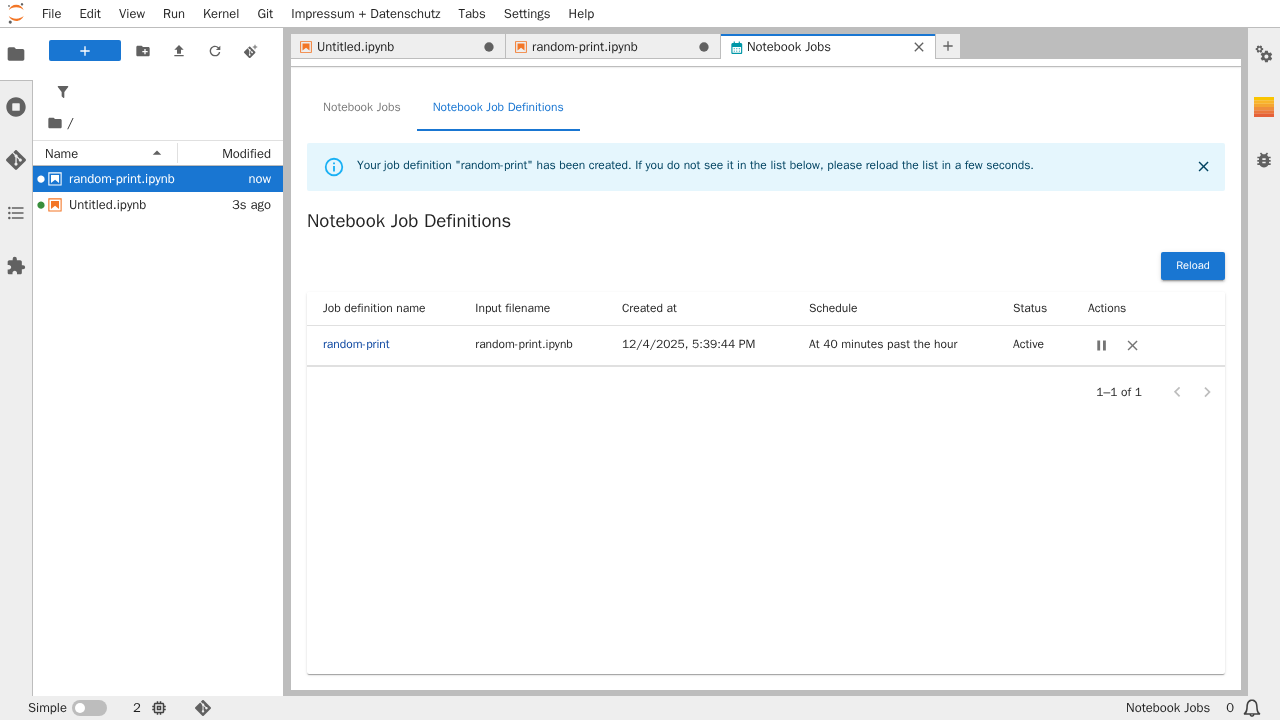
Nachdem der Notebook-Job erfolgreich erstellt wurde, öffnet sich ein neuer Reiter "Notebook-Jobs - Notebook-Job Definitions". Hier erhalten Sie einen Überblick über alle vorhandenen Notebook-Jobs.
Durch das Klicken auf den Job-Namen (hier: "random_print_job.ipynb) lässt sich die Übersichtsseite des Jobs öffnen.
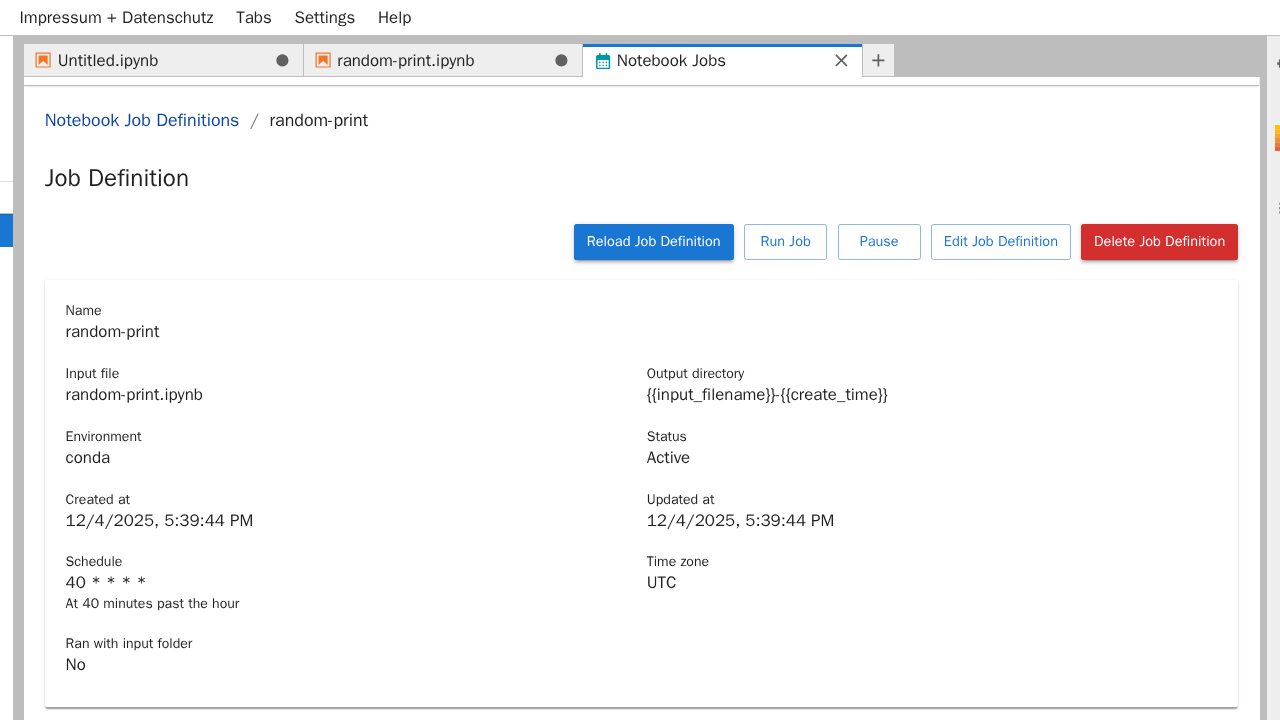
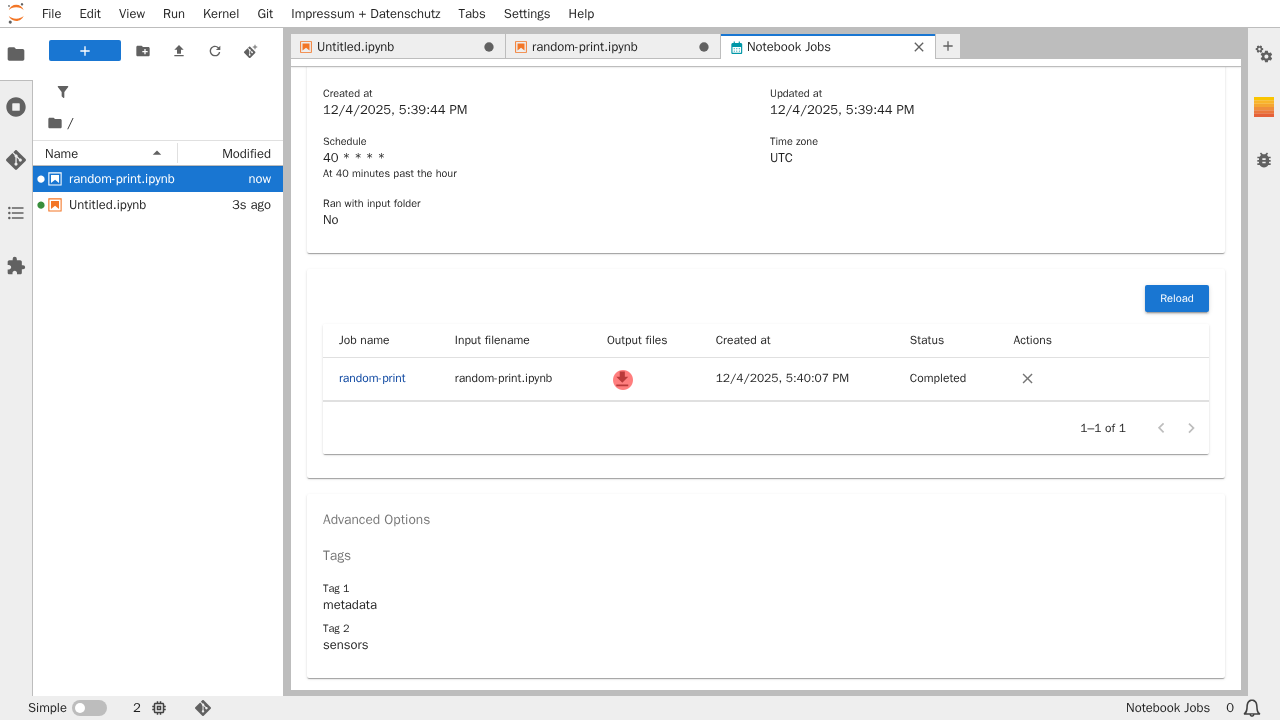
Auf der Übersichtsseite lassen sich die Eigenschaften, sowie die bereits abgeschlossenen Jobs (und die Ausgabedateien) des Notebook-Jobs einsehen.
Oben rechts befinden sich außerdem folgende Knöpfe:
"Reload Job Definition": Übersicht aktualisieren
"Run Job": Job sofort ausführen
"Pause": Job Pausieren
"Resume": Job wiederaufnehmen, falls dieser pausiert wurde
"Edit Job Definition": Die Job-Konfiguration bearbeiten
"Delete Job Definition": Den Job löschen
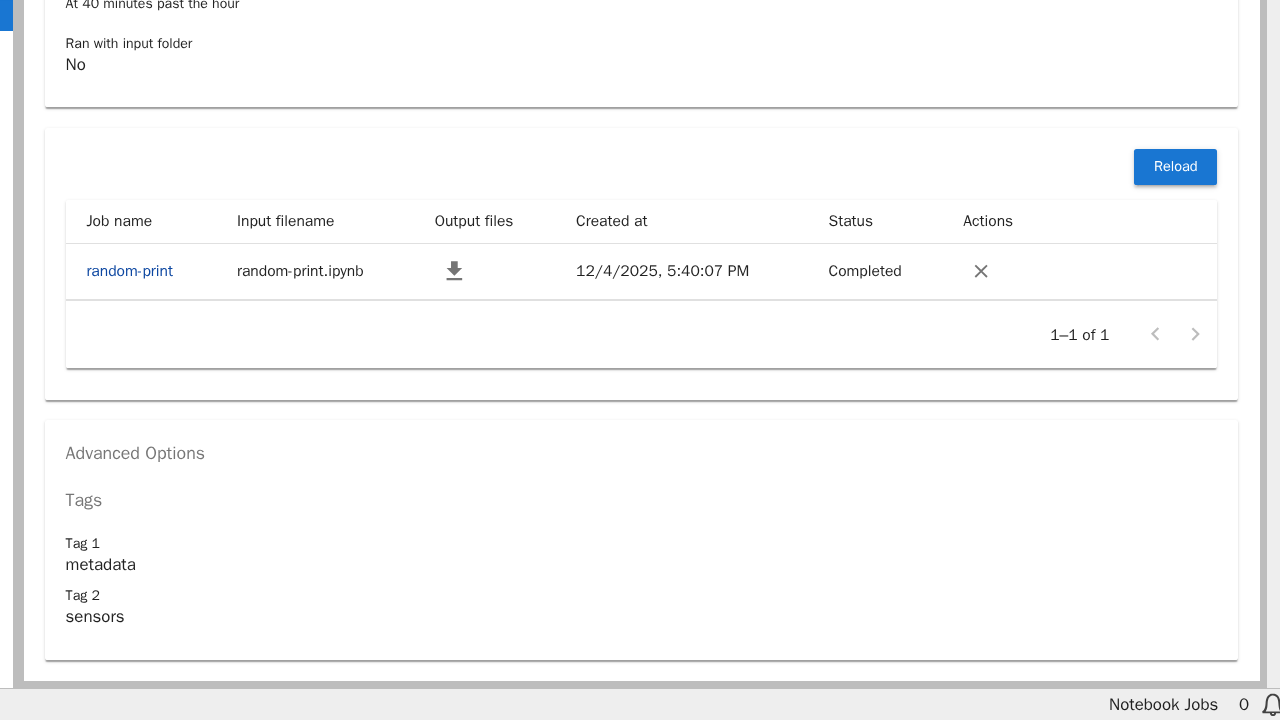
Um das Ergebnis bzw. die Ausgabedateien eines abgeschlossenen Jobs einzusehen, klickt man hierfür auf das Download-Symbol des jeweiligen Jobs.
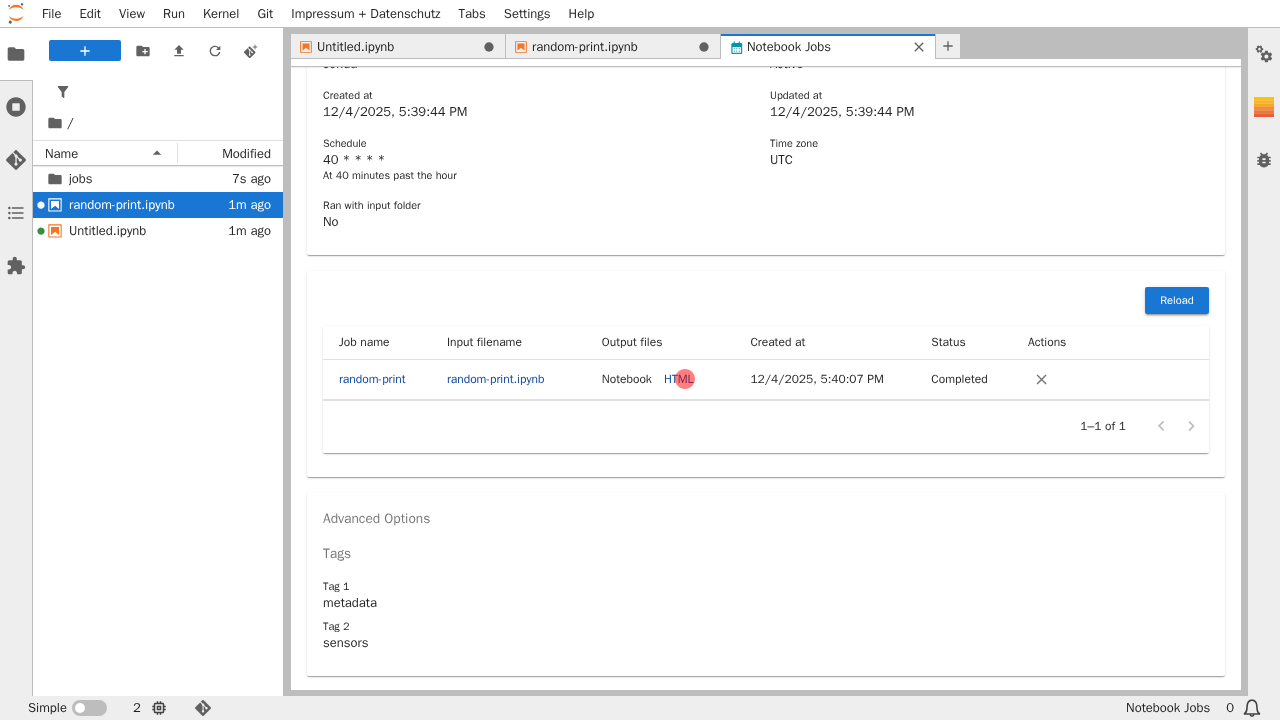
Nach einer kurzen Verzögerung erscheinen nun, anstelle eines Download-Symbols, die im Notebook-Job konfigurierten Ausgabedateien.
Durch das Klicken auf z.B. die HTML-Ausgabe, öffnet sich ein neuer Editor-Reiter in welchem der Verlauf und das Ergebnis möglicher Debugs oder print-Funktionen eingesehen werden kann.
Hinweis
Die Ausgabedateien werden unter "jobs/" im Hauptverzeichnis gespeichert:
Wenn es andernfalls zu Engpässen an verfügbaren Compute-Ressourcen im Kubernetes-Cluster kommen würde, können einzelne JupyterLab-Instanzen vom Kubernetes-System abgeschaltet werden um die Stabilität und Funktionalität der Core-Plattform sicherzustellen.
Dies ist bei normaler Nutzung der Plattform nicht zu erwarten, sondern nur, wenn eine unerwartet hohe Anzahl an JupyterLab-Instanzen gleichzeitig läuft.